That's All... For Now...
Today's the day I told myself would stop working on the framework, so that I must. A lot got done in the past week that made me feel... somewhat satisfied with my work. I managed to get skeletal animation working with a demo that shows off layered animations, or animation clip blending. This post reviews the final week of back-end development... but that doesn't mean I won't be back with more!
Hierarchies & Poses
Nowhere in the animal3D framework is the word "skeleton" mentioned. You're like, wait what? I wanted to keep things as general as possible, so I called it what it is: a skeleton is a hierarchy. Another common use for this is the scene graph, which is a misnomer because it's a tree. The data structure I implemented goes off of Jason Gregory's implementation in Game Engine Architecture, where each node in the hierarchy can have a virtually infinite number of child nodes by storing them in an array that is ordered by "depth" in the tree. However, in Gregory's implementation, the poses are stored with the nodes; I separated the two entirely. The hierarchy part is nothing more than a collection of named nodes, and the poses are nothing more than a collection of poses.

What's a pose? When we talk about a waypoint-based curve system, poses are the actual waypoints used to control curves. Poses are usually broken down into "channels", which are individual spatial components of a 3D coordinate frame orientation: rotation, translation and scale, each broken down further by axis. The screenshot here shows Maya's graph editor with a serious of waypoints on 6 different channel curves, the combination of which yields a single pose for the object being animated.
These two features come together as what I call a "spatial hierarchy": a set-of-sets of poses that reference a hierarchy; really it's a giant matrix of poses, with one "row" per each node in a hierarchy. Instead of having to set each pose for each node manually (which would absolutely suck), I implemented a HTR file format loader, which, in my opinion, is a very good format. After this was done, I tested it by drawing a skeleton on the screen using each "column" of poses (one pose per node at the same index) as a known sample to display.

Getting this right actually took a long enough time. I'd implemented HTR loaders before but I had forgotten the quirks of it; for example, to calculate the final local pose for each node (relative to its parent), rotations need to be stored as either matrices or quaternions and then concatenated with the base rotation, whereas for translation you just add the current pose with the base translation; my original guess was to generate a full transformation matrix for the base, one for each pose, and then concatenate to get the correct pose state. Anyway, after local poses are calculated, the final step to seeing a living, breathing skeleton (oxy-moron, much) is this little thing called forward kinematics, where the world-space transformation of each joint is calculated by multiplying by its parent's world-space transform, the algorithm shown in the above screenshot (from my slides). The root node's world-space transform is its local transform, but the rest of the joints only know how they are related to their parents; using logical inference, we can say that if we know how the parent relates to the world, and how a node relates to its parent, we therefore know how the node relates to the world. The result of all this is a full skeletal pose.
Mesh Skinning

To see the process working with a 3D character mesh, I used the only rigged and skinned character I have in my possession, a four-armed dancing freak of nature (which I modeled, rigged, skinned and animated all by myself several years ago). I loaded the mesh as an OBJ with skin weights, and implemented a vertex shader to skin the mesh. The only real animation-related requirement here is that, on top of the world matrix from the forward kinematics algorithm, each node in the hierarchy must store an additional matrix: the inverse of the result of forward kinematics for the bind pose. This matrix is then multiplied by the result of forward kinematics at any given time to produce the result. The math is shown in this screenshot, also from my slides. The logic: by taking the inverse of the bind pose world matrix, we're basically saying "go from the world pose at bind time to the local joint pose", then by multiplying this by the current world matrix, we are saying "now go to the current world state of the joint". Ultimately, the skinning matrix is the "delta" transform from the bind pose to the current pose.
Animation Clips
When dealing keyframe-based animation, each frame can be treated as an "animation state" or "sample" in an animation. A collection of samples can be called a "clip" or "sequence". Usually, text-readable exported animation formats from programs such as Maya will contain every single sample as a keyframe instead of the curves used to produce these frames, which is fine, because part of the point of animation programming is to reproduce the effects these curves. In any case, what these files don't mention is how the animator decided to divide up the timeline into clips or animation segments. These can be the short frame sequences that we might watch and describe as "run", "walk" or "idle". None of those are explicitly defined, you usually end up with a bunch of poses. So, the animation clip utility serves to take said frames and organize them into segments with names such as "run", "walk" or "idle", which makes it easier to define a timeline for each clip.
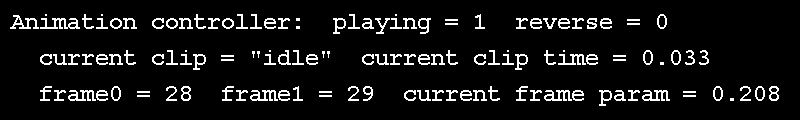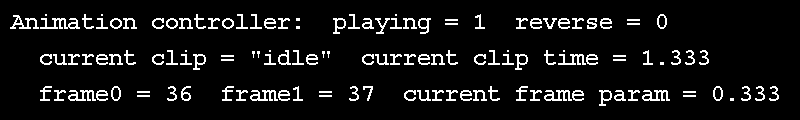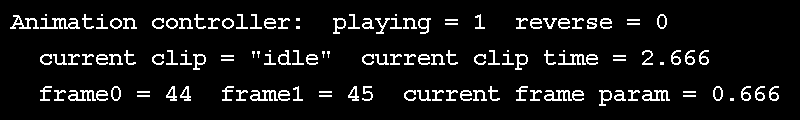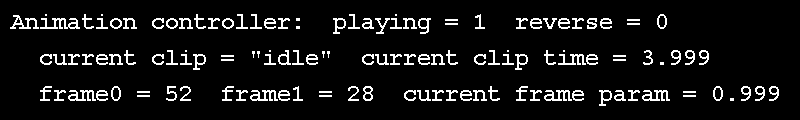
Wait, if keyframes are known, what about the unknowns? If we have exactly 5 keyframes and we want to see them all at an even interval in 5 seconds, it's clear that we see one keyframe per second. But does time move forward at a rate of 1 frame per second? Probably not. If we're running at 30 FPS, and we want our animation to be smooth, we need to see 30 frames, or samples per second; these are known as "in-betweens" or "samples", and the process of determining these is sometimes called "tweening". This is achieved by using two of the known samples, we'll call the first one "key 0" and the second "key 1", and interpolating between them. The in-between is controlled by an interpolation parameter, which is the relative time between the start and end of the current keyframe. All of this interpolation parameter control is implemented in animal3D as an interface known as an "animation clip controller", which takes the current time and figures out where we are in a clip, describing our "key 0", "key 1" and the interpolation parameter between them. This can be seen in action in the above GIF, rendered as a text overlay over the demo.
I spent a lot of time getting this just right because I knew it would be super useful with this next part...
Layered Animation & Blending

The cornerstone of any nutritious animation engine. With all of the above utilities in place, I actually completed this in only a few hours. The first part of this process is to have multiple instances of the animation clip controller running in tandem, each evaluating time for a different clip. These can be thought of as individual timelines, or layers. Each of the clip controllers provides the current and next pose indices ("pose 0" and "pose 1" respectively), so we know the two poses that we are blending between. The clip controller is also responsible for calculating the interpolation parameter between the two frames; we'll call this the interpolation parameter alpha, "alpha" because it describes the first stage in the process: calculating the current state of the hierarchy for each clip. I.e. we are not only blending between key frames; this stage helps us calculate in-betweens to blend. We'll call the in-betweens "clip samples". An illustration of this process is shown in the screenshot above.
There are three main blend operations that I explored here:
- Scale: literally scales the effect of a clip sample pose by blending away from the base pose; an interpolation parameter of 0 yields the base pose, whereas 1 yields the input clip. This behaves similarly to the alpha parameter, where "pose 0" is replaced with "base pose" or "bind pose".
- Blend/LERP: this is basically the LERP of animation blending: linearly interpolate from clip 0 to clip 1 using an interpolation parameter.
- Combine: this is commonly known as "additive" layering, where one clip happens and then the effect of another clip is stacked on top; basically you're combining the total effect of both inputs. The scale operation is particularly useful
The "scale" and "blend" behaviours have something in common: a secondary interpolation parameter that describes the relationship between inputs and outputs. We'll call this interpolation parameter beta, which is the input to some interpolation algorithm using pre-interpolated inputs. Where do beta parameters come from? Whereas alpha parameters are "local" to animation clips, beta parameters are usually controlled by some factor in the simulation, such as player controls or environmental factors triggering a character to change animations. The scale and blend operations can be seen in the GIF at the top of the post. They produce the user-controlled output using this algorithm:
- The "idle" clip (breathing, arms lowered) plays on channel 0 (the first clip controller).
- The "dance" clip (arms up, celebrating, it works, shit yeah) plays on channel 1.
- The effect of "idle" is scaled by user input (e.g. joystick).
- The effect of "dance" is scaled by a different user input.
- The effects of both scaled clips are blended by a third user input.
Wouldn't it be nice if we had a data structure or algorithm to describe this process? Luckily, we do. The organization of all this is done by implementing an "implicit tree" structure, which is really just a list of which clips blend with which and what order; this is called a blend tree. Each of the behaviours has a particular way to represent a node in a blend tree, called a blend node:
- Scale node: This diagram shows how the beta parameter is used to calculate the scaled clip pose, and how this translates into a blend node that would fit into a blend tree. The node only has one clip sample input and a beta parameter to control the result.


- Blend/LERP node: This works similarly to the alpha parameter, using pre-interpolated clip samples as the inputs, instead of keyframes. This is effectively bilinear interpolation for poses. The scale operation takes two clip samples and re-interpolates them together, using the secondary parameter, beta, to control the result. In quaternion-based implementations, the SLERP (spherical linear interpolation) method is used to blend rotations, while translation can be controlled using normal LERP.
-

- Combine/add node: This is another two-input node, but it does not involve interpolation. The result is simply the effect of clip sample 0 followed by the effect of clip sample 1. In some implementation, such as those that use matrices or quaternions, the order of inputs matters because a matrix/quaternion concatenation would be used; these are not commutative operations.



For all of the node diagrams, the "tree nodes" on the left are the input clips, after calculating the in-betweens using the alpha parameter, the operation in the middle is one of the three operations listed above, whose output is controlled using the respective beta interpolation parameter; the output is shown on the right.
Here is the blend tree representation of the process used to produce the GIF demo:

The result? Pure satisfaction. But it gets better: I only named three blend nodes up there... but that's not all you can do with this system!
Until next time...
I think for 5 weeks worth of work I've done just enough to be ready for my classes, animation programming in particular. I'm a little sad that I discovered so many flaws with the framework a couple weeks ago... and had the necessary urge to fix them all in a way that they'd never come back! I am an engineer, after all. If I could put one more week into this I would build some samples, but the one you see in the GIF at the top of this post is going to have to suffice. Let it be an inspiration to the students: it looks simple, but read this blog over and you'll see what it actually takes to get that working from literally nothing. That being said I'm pretty proud of what I've done to make animal3D into what it is.
Alas, the takeaways. Did I learn from this? Hell yes. I've always had a knack for complex 3D math, and have been very familiar with its applications, but some of the things I implemented for this framework have been on the engineering wish list for years. On top of that, one which I actually managed to complete is the art of the blend tree; before this I'd never actually programmed anything that went past the "alpha" interpolation phase.
What new things did I learn? Hotloading is pretty useful. Also, fun fact: I never bothered to try the "extern inline" combo in source code, which allows functions to be both compiled and inline, also super useful for dropping functions that should be .
What old things did I learn? Does that even make sense? Yes, I reinforced the fact that nothing will take the time originally estimated. There will always be fine details overlooked that cause days worth of nightmares along the way. I could go back in time through my repository commits and review all things that I should never do again... but in case I do these things again, I know why they occurred and how to fix them, which is quite possibly the most invaluable thing one could learn in the domain of programming hard skills. Soft skills-wise, one needs to accept that real-time cannot be controlled, and shit happens. But when you're an animation programmer, time is all you really have control over, so make use of it virtually.
I leave you with this picture of a cat-duck, because blending. Thanks, internet. And thanks for reading, see you again soon.